
历史数据的爬取有三种方式:
1.利用ghtorrent提供的历史数据。但是没有提供homepage字段;需要另爬readme
2.先用/repositories/ API 先获取项目列表,然后利用repos/:owner/:repo API爬取详细信息。需要另爬readme
3.先用/repositories/ API 先获取项目列表,然后用获得的项目url爬取项目主页然后抽取信息。但是没有日期,没有language;可以直接抽取readme
1.利用https://api.github.com/search/repositories 持续爬取。但是问题是,如果项目是fork的话,没有返回父项目的信息
1.利用ghtorrent提供的历史数据。但是没有提供homepage字段;需要另爬readme
2.先用/repositories/ API 先获取项目列表,然后利用repos/:owner/:repo API爬取详细信息。需要另爬readme
3.先用/repositories/ API 先获取项目列表,然后用获得的项目url爬取项目主页然后抽取信息。但是没有日期,没有language;可以直接抽取readme
综合考虑:后续处理必须用到homepage,且尽量保证信息的完整性,计划用第二种方式
1.利用https://api.github.com/search/repositories 持续爬取。但是问题是,如果项目是fork的话,没有返回父项目的信息
2.还是利用/repositories/ API
目前打算用第二种方式,因为它返回的数据本身都是按创建时间排序的
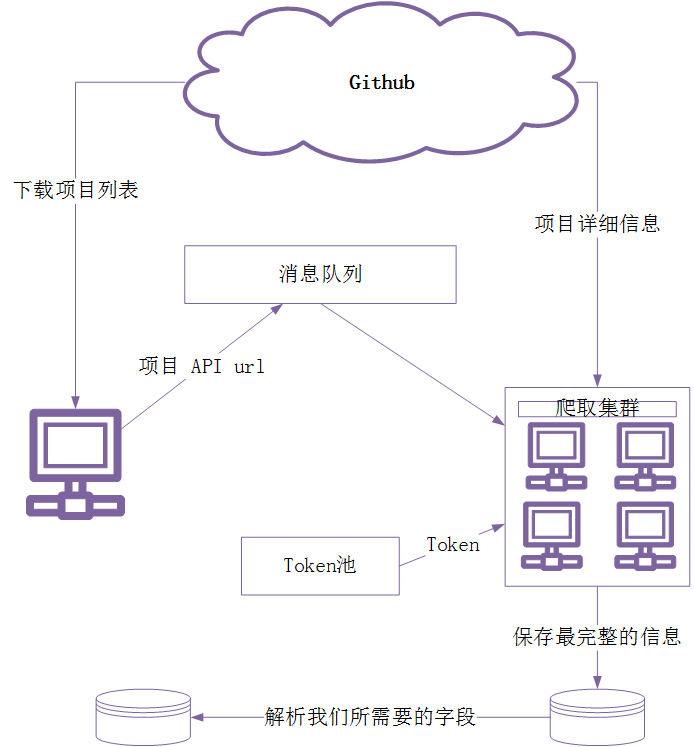
因为数据量太多,想用分布式的形式爬,大体思路如下:
- 当前状态 新增
- 选定优先级 正常
- 指派给 LiZX
- 里程碑 --
- 开始日期 2016-04-19
- 结束日期
- 预计工时(H) 0.00 小时
- 完成度 0%
- 关联Commit 无

