
项目简介
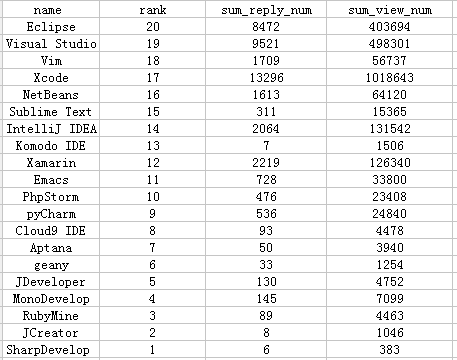
论题:基于用户反馈的开源软件热点分析方法与平台 分析协同开发社区的开源软件的指标,基于知识分享社区的用户反馈信息定义开源软件排序的度量方法,由此得到最受用户欢迎的开源软件排名。

1.重新建立线性模型(参照DBEngines的实际排名):view_num加入了时间惩罚因子(view_num/month),回答数并不会随时间线性增长,只要解决了问题就不会增长了。

线性模型为:
采用R语言gvlma包中的gvlma()函数检验线性模型假设是否合理:

结论为:合理,从Global Stat栏看p=0.376,满足了线性回归模型下的所有统计假设。
2. 采用Learning to Rank(学习排序)算法。(LTR在附件中有简单介绍)
开源软件的类型可以看成输入的查询字段,软件的排序结果即对应相关程度label,训练模型采用DB数据,测试采用IDE数据。
采用范强师兄的建议,在考虑帖子来源平台这一因素时,直接将数据按平台(oschina,stackoverflow)、按类型(topic,news,blog)划分,比如oschinaTopicReply 、oschinaTopicViewNum、csdnNewsReplyNum。将数据分为多维向量。对于这种融入多种信息,有多个特征向量的排序模型,学习排序算法能给出很好地答案。
实验时分别采用了4种LTR算法:MART (gradient boosted regression tree), AdaRank ,Coordinate Ascent,LambdaRank;以及湛云师兄提出的(rank1)和线性模型。
排序结果如图所示:(参考PYPL的IDE排名)

用NDCG评估排序算法:

从上图可得知,学习排序算法给出了比较好的排序结果,特别是Adarank和Coordinate Ascent方法。线性模型的排序结果也很不错。
但是目前还不可断定哪种LTR模型最准确,训练数据太少(可参照的实际数据类型比较难找),接下来需要多查找比较准确的软件排序信息,来训练模型更全面更准确。
后续可参照infoworld BossieAward 2015年的开源软件调查数据。
LTR排序算法实现参考:
http://people.cs.umass.edu/~vdang/ranklib.html
1. 对项目和帖子关联后的数据属性分析
从数据库抽取近2000条开源项目数据分析,发现下载量(download_num)和另外两个属性(帖子数量(relative_memo_num)、浏览量(view_num))都成负相关,分析成因是由于平台爬取的下载量的数据仅来自sourceforge社区,数据来源单一,有平台倾向性,所以下载量这个属性不准确,是不可用的。

对于帖子数量(relative_memo_num)、浏览量(view_num))两个属性,观察两个属性的相关度:cor=0.897>=0.8 (强相关)
对于强相关的数据,可认为对排序的贡献度是一样的,所以可以只取一个属性作分析,由于课题旨在分析用户反馈信息,所以取帖子数量(relative_memo_num)进行分析。
另外,考虑到帖子数量与项目的存在时间有关系,采集2015年1月1日~2016年1月1日的帖子数据。
2. 实现湛云师兄提出的评估算法

排序结果:

结果:NDCG = 0.886 还可以继续优化。
对于浏览数和回答数,可以根据其对帖子的影响力进行加权,还可以考虑帖子来源,作者信息。
NDCG(Normalized discounted cumulative gain):是用来衡量排序质量的指标。
在传统评价标准基础上考虑了排序结果和排序位置的影响, 用来评价排序结果中顶部序列的准确性。

Zn是归一化参数, 它使最优排序的NDCG始终为1,j表示排序位置,r(j)表示评分级别。
3. 评估帖子的对项目的重要程度
参考pagerank算法,一个项目的重要程度,由和它关联的帖子数目和帖子的重要程度决定。影响帖子的特征变量有:
浏览数(view_num_crawled),回答数(replies_num),支持数(vote_up_num),收藏数(collection_num),来源平台(source),作者信息等等。
目前平台能利用的数据有帖子的浏览数(view_num_crawled) ,回答数(replies_num),来源信息。
(1)帖子的浏览数(view_num_crawled) ,回答数(replies_num),随着发布时间的增长,数量会增多,所以应该加入时间惩罚因子。
对于回答数这个属性,对于帖子类型为问答类型的不太准确,原因如下:某个答复若对一个帖子回答的足够完善,答复数并不会增多,能体现答复对帖子的影响力的,应该对答复的支持数(另外stackoverflow的回答是可编辑的,可以直接修改回答),所以对帖子重要性的贡献度考虑要减少一点

(2)衡量帖子的来源平台:
参考 https://linux.cn/article-6899-1-rel.html 提到的指标来衡量一个社区。其主要提到5个指标:
1. 社区活动(Activity),比如项目的提交次数,讨论的帖子数量。
2. 社区规模(Size),指的是参与到这个社区的人数。
3. 社区表现(Performance),如解决和关闭问题的时间。
4. 社区人口特征(Demographics),人员的流动,新增或流失用户。
5. 社区多样性(Diversity),人或者组织参与的多元化。
ossean平台帖子的来源主要有:
Stackoverflow, CSDN, 51CTO Blog, OSChina, Iteye Blog,CN Blog,Slashdot。
对应到帖子平台,参考指标可以具体化为帖子的数量(注意平台发展时间),短时间更新数量,用户人数,问答的响应时间。
对于有多种帖子类型的社区,可以针对帖子的类型:blog(博客)news(新闻)topic(讨论),将大社区可以分为几个小社区,比如CSDN 可以分为csdn blog ,csdn news ,csdn topic。因为每个类型活跃的用户群有差别,一个用户可能在一个平台上做问答,在另一个平台上写博客,比如qq和腾讯微博。
4. 建立排序模型
(1)简单线性回归分析
取项目的帖子的浏览数和回答数,用R语言做线性回归分析:
DB:

排序时将排名逆序排,与属性成正比

结果如上图所示:
Rank=7.835-1.581*10^-3*memo_reply_num+6.766*10^-5*memo_view_num
IDE:

(2)可以参考learning to rank(学习排序)的Prank算法进一步分析。
X为帖子数据集,包含多个特征向量,W为权重向量。
Score(x)=w1*x1+w2*x2+w3*x3+...+wn*xn
Prank的决策函数如下:
![]()
定义了K个等级标签,每个标签对应一个阈值分数,它通过K个阈值b把空间划分为K个连续的子空间,每个子空间对应一个等级。对每个样本,先计算权重w与xi的内积w·x,找出所有满足w·x-br中最小的br,并将此br对应的序标号xi作为排序模型对样本的预测排序结果.然后比较实际排序结果和预测的排序结果,更新排序模型(更新权重w和阈值分数b)。

 ,按照这个思路不断深入分析,一定能够不断提高排序准确度!
,按照这个思路不断深入分析,一定能够不断提高排序准确度!


将用户帖子数作为排序依据,对ossean平台上的DB、开源大数据工具、IDE排名分析。
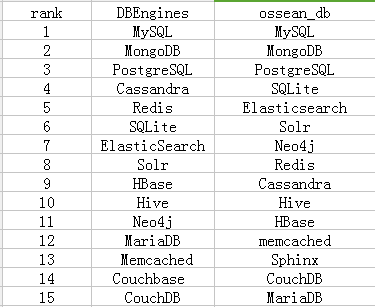
1.DB
参照DBEngines上的数据库排名:
取DBEngines排名前20个开源数据库软件,在ossean中取出对应的开源软件,并依照用户帖子数relative_memos_num对其排序,然后对比如下:
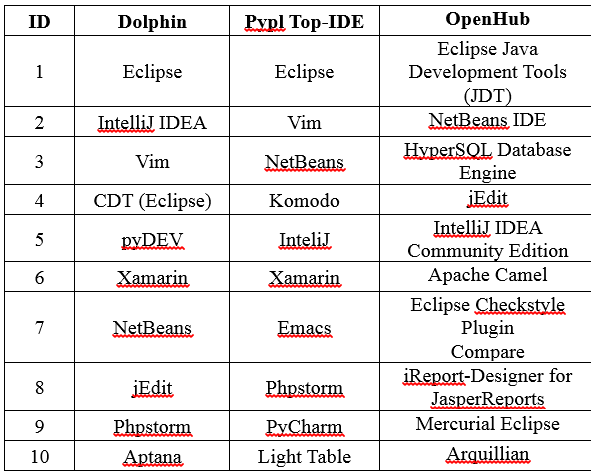
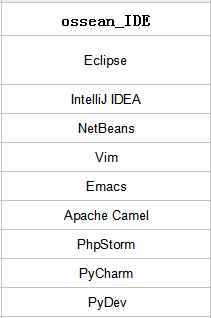
2.IDE
参照下图:
3.开源大数据工具
参照2015 Bossie评选:最佳开源大数据工具,结果如下:
(对于Bossie评选的数据,取前10)
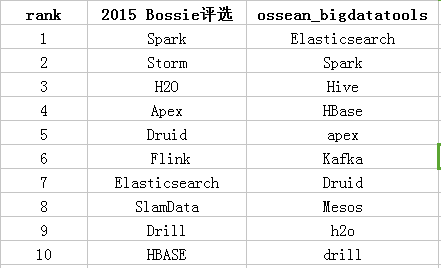
结论:
从对比图中可以看出,仅凭用户帖子数作为软件排序的依据并不准确。
分析:
1.主要原因:用户帖子数即为用户讨论量,只依据这一个参数太片面,应当综合其他参数,项目属性等。例如DBEngines结合了用户讨论,搜索引擎的搜索量,还有工作需求等等;
2.有一些软件和特定的开发环境,操作平台绑定,比如DB中的SQLite(Android),IDE中的vim(类Unix),对该绑定软件的讨论会增加帖子量。
3.项目与帖子匹配时,根据标签,一封帖子会和多个与之有关的项目关联,是否有考虑帖子偏重。
4.帖子本身有一些属性,比如回帖数,浏览数等,应综合考虑加权分析。

