
项目简介
主要对博士选题开题进行学习、交流

V2016.3.23(完成稿):
根据师兄们的意见,对PPT进行了修改完善,并梳理故事
--------------------------------------------------------------------------------------------------
V2016.3.22(完成稿):
对开题报告进行了小的改动,在PPT中增加了生态系统的介绍等相关知识
---------------------------------------------------------------------------------------------------
V2016.3.21(完成稿)-1:
对开题报告一些细节进行了完善,对PPT相关内容进行修改并从头到尾梳理了一边思路
----------------------------------------------------------------------------------------------------
V2016.3.21(完成稿):
完成开题PPT
----------------------------------------------------------------------------------------------------
V2016.3.20(完成稿):
完成所有开题报告内容,对研究内容做了重新梳理,将参考文献等内容全部完成
------------------------------------------------------------------------------------------------------
V2016.3.17:
结合与尹老师、Filkov教授的讨论,我想把开题报告的背景与研究内容进行如下调整:
1. 背景:
(1). 大众参与的软件开发模式形成开源世界强大的软件生产力
(2). 大量的软件群落促使开源生态系统的形成
(3). 大量外围贡献的汇聚是软件群落不断生长的关键
2. 研究内容:
(1). 基于核心软件角度的群体贡献汇聚方法
a. 围绕核心软件的软件群落定位与发现
b. 面向核心软件开放程度的多维度度量方法
c. 基于大规模群体协同的外围贡献评价方法
(2). 基于外围软件角度的群体贡献汇聚方法
a. 外围开发者的贡献行为模式挖掘
b. 面向需求创意的高效汇聚方法
c. 面向代码贡献的高效汇聚方法
---------------------------------------------------------------------------------------------
V2016.3.14:
对研究内容进行了新的修改,并对挑战等内容进行了修改,目前研究内容是:
(1)基于软件信息网络的开源软件生态系统构造方法
(2)面向开源软件生态系统生长的群体协同模式挖掘
(3)基于大规模群体协同模式的贡献汇聚方法
1)面向需求创意的高效汇聚方法
2)面向代码贡献的高效汇聚方法
------------------------------------------------------------------------------------------------
V2016.3.13:
补充了一些内容,对于研究点的阐述感觉还不是很到位,目前主要是:
1)面向开源软件生态系统生长的群体协同机理研究
2)面向开源软件生态系统生长的群体贡献汇聚方法
3)面向开源软件生态系统生长的群体贡献度量方法
自己感觉还不太好,还是不够提炼
------------------------------------------------------------------------------------------------
V2016.3.11:
基本完成了文献综述以及一部分研究内容
------------------------------------------------------------------------------------------------
V2016.3.10:
主要对研究背景、研究问题、研究意义等进行初步的梳理,其中对于研究背景的描述以及研究点的描述还需要进一步提炼
------------------------------------------------------------------------------------------------

2016年3月6日:
面向开源生态系统生长的群体协同机理研究??
1. 开源生态系统的内涵和边界是什么,如何变化?
本周我一方面对现有关于“software ecosystem”的研究进行了整理,发现目前对于开源生态系统的定义主要是借鉴对于“software ecosystem”的定义,主要分为以下五个:
1)最早是2003年Messerschmitt和Szyperki提出,“Traditionally. A software ecosystem refers to a collection of software products that have some given degree of symbiotic relationships.”
2)引用最多是2009年Jansen等提出,“We define a software ecosystem as a set of business functioning as a unit and interacting with a shared market for software and services, together with the relationships among them. These relationships are frequently under-pinned by a common technological platform or market and operate through the exchange of information, resources and artifacts.”
3)2009年Bosch提出,“A software ecosystem consists of the set of software solutions that enable, support and automate the activities and transactions by the actors in the associated social or business ecosystem and the organizations that provide these solutions.”
4)2010年Bosch和Bosch-Sijtsema提出,“A software ecosystem consists of a software platform, a set of internal and external developers and a community of domain experts in service to a community of users that compose relevant solution elements to satisfy their needs.”
5)2010年Lungu等提出,“A software ecosystem is a collection of software projects which are developed and evolve together in the same environment.”
共同点都是指相同的软件平台或环境,其中有商业利益或用户需求以及他们的关联关系,但这些定义用在开源生态系统中我觉得存在一定局限性。
在开源生态系统里(以github中为例),我认为构成要素有:
1. 核心软件项目(一个开源生态系统源头,例如开发框架或库)、相关项目(基于核心项目开发的子项目、为核心项目开发插件的子项目、以及单纯fork出来的子项目)
2. 软件版本库(source code、commit)、缺陷托管工具(issue、pull-requests、comment)、文档资料(wiki、document)、跨社区数据(SO post、URL link)
3. 开发者(manager、internal developer、external developer)
4. 间接用户(customer)
5. 其他相关要素
2. 开源生态系统成长过程中的群体协同机理
(1) 影响开源生态系统成长的因素分析
a. 一个核心项目自身开放程度(openness)对于形成一个开源生态系统的影响
b. 外围子项目对于核心项目的贡献(code, requirement)对于形成一个开源生态系统的影响
c. 如何促进和加快?
(2) 开源生态系统中涉众的管理
随着生态系统的不断生长,核心项目如何进一步扩展自己,如何管理不断加入的新涉众(提供需求、贡献代码等),如何促进他们更好地为生态系统服务?
3. 服务开源软件生态系统的工具
面向开源生态系统的知识汇聚机理与方法研究???
研究动机:
在过去,一般是一个公司的一个开发小组利用一个中心版本库来开发一个项目。自从分布式系统的诞生以及web2.0技术的兴起,现代软件开发过程中的协作、编码、部署、维护等模式发生了巨大改变,软件系统的规模、复杂程度也在不断增加。一个好的软件项目会逐渐成长成一个以它为中心,衍生出众多的子项目以及知识的软件生态系统,从而使得许多传统软件工程研究的问题变得局限,例如在一个以开发框架为核心的软件生态系统中,核心项目的开发需要时刻考虑其他子项目的需要。
2003年,Messerschmitt首次提出“软件生态系统(software ecosystem)”的概念,他给出的定义是,“一组有着相同共生关系的软件项目集合”。在今天基于网络分布式开发的背景下,现有的研究对于“software ecosystem”定义,说是一组在相同环境(相同社区、相同公司或者相同技术平台)下共同开发共同演化的项目集合,其本身还是强调在相同的环境下的项目的集合,但我们认为在如今开源世界里,软件生态系统的范围变得更加庞大,不仅仅局限在单一的社区或技术平台,很可能是跨社区的知识汇聚,例如Rails托管在Github上,但其在StackOverflow上同时拥有大量的相关的问答帖子。
放在开源世界里,如何合理的定义开源软件生态系统是一个十分挑战的问题。在开源软件生态系统中,如何识别不同类别的知识,这些知识如何传播等等,这些分析都有助于在一个全局的角度为核心项目的开发提供建议,促进整个生态系统的健康发展。(意义部分还需要进一步提炼)
研究目标:
基于开源软件的大规模数据,定义并构建开源软件生态系统,在此开源软件生态系统中,分析项目间知识汇聚的机理,利用这些机理设计机制并实现服务开源软件生态系统的可视化工具。
研究问题:
1. 开源生态系统的内涵和界定是什么?
(1) 开源生态系统是如何构成的?
基于大规模开源数据,如何构造开源生态系统?构成开源生态系统的元素有哪些?
(2) 开源生态系统中各元素的关联关系是怎样的?
大量优质的开源软件使得开发者们在开发自己的项目时候可以复用已有的组件和框架,这样的依赖促进了软件开发效率,但依赖的越多(依赖的代码越多、依赖的项目越多)也增加了项目本身的复杂程度,给开发者开发带来难度,所以我想研究一下几个问题:项目依赖的越多好还是越少好?项目的这种依赖随着开发进行是否发生改变?不同子项目对于核心项目的影响是否相同?
2. 开源生态系统中的知识汇聚是怎样的(代码贡献、需求)?
(1) 如何识别这些知识?
开源项目每天会产生大量的知识,核心项目如何识别和区分那些来自不同子项目的知识?这些知识的汇聚对于核心项目开发的影响是怎样?对于核心项目来说,哪些知识是开发者需要的。
(2) 如何加快这些知识的汇聚效率?(@-mention)
在这样复杂的生态系统里,加快各类知识的汇聚效率是十分重要的。例如,@-mention使得开发者可以更紧密的联系,促进交流。
3. 服务开源软件生态系统的的工具
现有的软件项目工具主要还是针对单一项目本身,缺少服务全局生态系统的工具。
(1) 开源生态系统的可视化工具
(2) 开源生态系统中各类知识汇聚的分析工具

2016年2月25日:
针对余跃师兄的建议,我将重点放在那些实际用rails做框架的项目上,今天我利用rubygems.org(托管所有gem的网站),通过它的API可以获取每个gem的信息(gem的owner、gem的托管地址等),其中有3291个gem的代码是托管在github上的(其中就包括rails),通过gem里的dependency信息(这里我只考虑了Devdep,即只考虑开发需要的dependency,没有考虑运行的dependency),可以构建github上的ruby项目网络(1563个节点,2910条边):

2016年2月24日:
这两天我利用GHTorrent最新数据(dump-2016-2-1),分析了Rails生态系统相关内容,得到了一些实验结果,希望可以和老师、师兄们一起讨论:
1. Rails生态系统的构建:
假定认为项目(repo)的name或者description含有“ruby on rails”,说明该repo和Rails相关,通过筛选得到69243个repo,其中9075个项目是从Rails fork出来的。
通过对这些项目的语言统计,如下图(项目数前20的语言),78.5%的项目语言是ruby,前几基本上是网络相关的语言,符合常识。
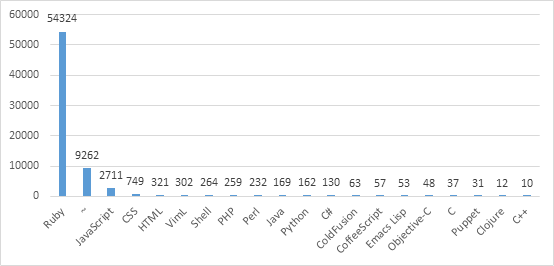
接下来,我对这些Rails生态系统里的项目进行了学习,发现大致可以分为以下几类:
(1)fork出去的项目,forked from Rails: 9075 (13.2%)
(2)Rails提供的demo,Rails demo(demo_app/first_app/sample_app): 29380(42.4%)
(3)课程学习,Course:1127(1.6%)
(4)为Rails服务的插件等,for Ruby on Rails: 11226 (16.2%)
(5)基于Rails构建的系统等,built with Ruby on Rails: 2184 (3.2%)
(6)其他类型,others:16188 (23.4%)
2、进一步挖掘:
基于上面形成的Rails生态系统,我试图了解,这些衍生出来的项目是否对Rails项目自身产生贡献,这其中的贡献汇聚是怎样的,我目前试图从开发者的角度进行切入,分析其他开发者(非Rails成员)从接触Rails建立Rails相关项目,到真正为Rails项目做贡献过程中蕴含的规律。目前探讨以下三个问题:
(1)其他开发者关注(watch)Rails与自己使用Rails(建立Rails相关项目)的关系?
目前Rails共有31332个关注,除去自己的成员,有6824(21.8%)个关注来自Rails生态系统里的项目owner,其中:
5711(83.7%)个开发者是在watch了Rails之后才建立Rails相关项目,平均时间是21.8个月;
1113(16.3%)个开发者是在watch了Rails之前就建立Rails相关项目,平均时间是11.0个月。
说明,大部分的开发者应该是先关注Rails这个项目,熟悉后才自己尝试建立项目,平均要花近2年的时间,少部分是自己先建立项目,然后再关注Rails(可能自己建的项目有问题,所以很快关注Rails,时间也短许多)。
(2)其他开发者在Rails中评论与自己建立Rails项目的关系?
Rails中comment(这里我先只考虑了issue comment)共有107812个,其中4237(4%)个来自Rails生态系统的项目owner,其中:
1429(34%)个开发者是在Rails评论之后才建立了Rails相关项目,平均时间是11.5个月;
2808(66%)个开发者是在Rails评论之前就建立了Rails相关项目,平均时间是11.6个月;
说明大部分的开发者可能是建立了Rails项目,熟悉之后才开始参与Rails项目中去,平均需要1年。
(3)其他开发者在Rails中提交issue与自己建立Rails项目的关系?
Rails共有24107个issue(包含pull-requests),2734(11.3%)个来自Rails生态系统项目的owner,其中:
852(31%)个开发者是在Rails提交了issue后才建立Rails项目,平均时间是10.5个月;
1891(69%)个开发者是在Rails提交了issue前就建立Rails项目,平均时间是10.0个月。
说明大部分的开发者也是先建立Rails项目进行学习,熟悉后才向Rails做贡献。
总结:
我初步的思路是,Rails生态系统里的项目owner,他们建立了Rails相关的项目(相当于是Rails的扩散),他们在使用或学习过程中,可能会反过来作用于Rails,向Rails做贡献(关注,评论,提交issue,提交代码等),这就形成了贡献的汇聚。
目前分析结果和常识差不多,即大部分的开发者(非Rails成员)应该是先关注Rails这个项目,一段时间后才自己建立Rails相关项目,再过一段时间才向Rails做贡献。
这只是我初步探索的一些实验结果,希望可以和老师、师兄们讨论下,再进行下一步。
2016年2月23日:
Ruby on Rails项目正在形成属于自己的Rails生态系统,它不仅拥有很多子项目,很多其他项目也基于Rails进行开发,例如Basecamp、github。除了github上形成的Rails网络,它在Stackoverflow上也拥有着大量的问答帖子信息。
目前的工作重点是,先尽快以Rails生态系统为研究对象,构造出其基本的生态网络,在此基础上结合已有的工作,争取尽快形成开题的完整思路。
(1)CiBuildsCrawller.py: 从数据库中读取builds_id,然后爬取builds文件;
(2)CiJobsCrawller.py: 解析builds文件,读取每个build下的job_id,然后根据job_id爬取job的log文件,如果爬取失败就将missing的job_id存到单独的missing表,所有爬取任务结束后,重新扫描missing表的job_id,继续爬取(爬取成功删除missing表里对应的job_id),直到所有job都爬取完毕;
(3)CiJobTestsParser.py:读取job文件,解析基本的test信息;
(4)CiJobTestsFilesParser.py: 进一步解析test的文件对应信息
数据库表结构:
(1)ci_builds_jobs_yu:
CREATE TABLE `ci_builds_jobs_yu` (
`Id` int(11) NOT NULL AUTO_INCREMENT,
`repo_id` int(11) DEFAULT NULL,
`builds_id` int(11) DEFAULT NULL,
`job_id` int(11) DEFAULT NULL,
PRIMARY KEY (`Id`)
) ENGINE=MyISAM AUTO_INCREMENT=45620 DEFAULT CHARSET=utf8;
(2)ci_builds_yu:
CREATE TABLE `ci_builds_yu` (
`Id` int(11) NOT NULL AUTO_INCREMENT,
`repo_id` int(11) DEFAULT NULL,
`builds_id` int(11) DEFAULT NULL,
PRIMARY KEY (`Id`)
) ENGINE=MyISAM AUTO_INCREMENT=7649 DEFAULT CHARSET=utf8;
(3)ci_jobs_tests:
CREATE TABLE `ci_jobs_tests` (
`Id` int(11) NOT NULL AUTO_INCREMENT,
`repo_id` int(11) DEFAULT NULL,
`builds_id` int(11) DEFAULT NULL,
`job_id` int(11) DEFAULT NULL,
`test_id` int(11) DEFAULT NULL,
`running_command` longtext,
`run_options` int(11) DEFAULT NULL,
`running` longtext,
`finished_time` float DEFAULT NULL,
`runs_time` float DEFAULT NULL,
`assertions_time` float DEFAULT NULL,
`runs_count` int(11) DEFAULT NULL,
`assertions_count` int(11) DEFAULT NULL,
`failures_count` int(11) DEFAULT NULL,
`errors_count` int(11) DEFAULT NULL,
`skips_count` int(11) DEFAULT NULL,
PRIMARY KEY (`Id`),
KEY `job_id` (`job_id`),
KEY `builds_id` (`builds_id`),
KEY `test_id` (`test_id`)
) ENGINE=MyISAM AUTO_INCREMENT=714284 DEFAULT CHARSET=utf8;
(4) ci_jobs_tests_file:
CREATE TABLE `ci_jobs_tests_file` (
`Id` int(11) NOT NULL AUTO_INCREMENT,
`repo_id` int(11) DEFAULT NULL,
`builds_id` int(11) DEFAULT NULL,
`job_id` int(11) DEFAULT NULL,
`test_id` int(11) DEFAULT NULL,
`running_file` longtext,
PRIMARY KEY (`Id`),
KEY `job_id` (`builds_id`),
KEY `builds_id` (`builds_id`),
KEY `test_id` (`test_id`)
) ENGINE=MyISAM AUTO_INCREMENT=8315307 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
初步思考:
(1)项目间汇聚:
1. 目前Rails项目十分火,很多项目都是基于Rails进行开发,例如Basecamp、github,还有Shopify、Airbnb、Twitch、SoundCloud等,这些项目也都在github上进行托管;
2. 是否存在这样的现象,这些项目中发现的问题提交到Rails中,进一步被Rails采纳?
(2)跨社区汇聚:
1. Stackoverflow上目前有230423个帖子打了ruby-on-rails标签,这些帖子中是否有的问题被纳入Rails中?

背景:
在实际软件开发过程中,软件的release大致可以分为两种:feature-based(一定功能实现后进行release)和time-based(一定时间进行release)。一般开发者都希望自己的贡献(代码、修复bug等)能够尽快的被纳入进稳定的release中,这样可以提高他们的声誉。feature-based的release方法由于具有时间不确定性,一旦突然通知将要release了,开发者就得赶代码赶材料。而time-based的release方法因为知道即将release的时间,开发者可以很好的有针对性的进行准备(即便错过了一次release,下次release的时间也大概知道)。
有规律的release方法可以使开发者清楚了解自己贡献会在很短时间内被采纳,也可以促进用户反馈,并且有规律的release也会增加外围开发者去参与贡献。
传统的有规律的release一般也都是管理者人工管理,形成计划文档或者自己把握,对于其他开发者(尤其外围开发者)是不可知的,他们不知道这个软件下一次release是什么时候?而在目前大规模群体协同进行软件开发的背景下,会有大量的外围开发者希望自己的贡献能够尽快被纳入稳定的release中,这就使得release predictable显得尤为重要。
之前我对github中milestone进行了初步分析,可以认为milestone就是一种release predictable的工具。管理者可以有效地对issue、pull-requests进行管理,开发者也可以根据时间点合理安排工作。通过milestone,我们可以知道哪些贡献被纳入进下一个release,这些贡献需要逐重解决(统计发现有milestone标记的issue的评论数、参与人数都比没有milestone标记的要多,评论时间间隔要小,说明讨论更加频繁)。
拟研究问题:
1. 从贡献者角度:什么样的贡献可以被纳入release(进一步,纳入稳定release)?能否自动判断?
我们认为被纳入release的issue应该是好的重要的,那么我们需要分析有无被纳入release的issue或pull-requests的特点,从而指导开发者更好地贡献代码或修复bug。
初步进展:除了通过milestone标记判断,在Rails中,我利用commit信息,可以回溯找到对应的pull-request,从而找到那些没有milestone标记但被纳入release的pull-requests。进一步,通过判断commit中“Fixes #”以及pull-requests中的“#”链接,可以找到那些没有milestone标记但被纳入release的issues信息。在此基础上,分析有无纳入release的issue的特点,进一步可以设计算法,实现自动判断,当新的issue或pull-requests来后,可以自动添加milestone或标签,告诉管理者可以放到下一个release中。
2. 从管理者角度:怎样合理设置release时间?
统计发现,github中大部分的milestone建立后都没有设置截止时间,即便设置截止时间的也有很多最后超过了的。我们能否通过分析那些著名项目的milestone特点,来为管理者提供建议:什么时候可以开始准备下一个release了?大概需要准备多久?进一步进行自动预测。
可行性分析:
1. 虽然本身有milestone标记的issue数目很少,但通过commit信息回溯关联,可以得到足够的分析样本,来分析有无纳入release的issue特点;结合文本信息,通过训练也可以实现简单的issue分类或milestone标记;
2. 通过前期的分析,github中那些著名的项目的milestone设置是存在一定规律性的,加上通过1补充的issue与release信息,应该可以实现对milestone时间的预测;
与开题及出国工作的联系:
1. 目前开题还是想做开源社区中贡献的汇聚与管理,这个大点对于需求的汇聚和管理同样适用,汇聚包括很多层面,项目内汇聚、项目间汇聚、跨社区汇聚。项目内汇聚主要研究如何激发开发者参与讨论、进行贡献,项目间和跨社区汇聚主要分析汇聚现象和规律。
2. 管理层面,主要研究如何更好的管理贡献。milestone就是管理的工具,目前github中milestone的使用还存在一定的问题(用的不多,用的不好),所以想通过这部分研究来看是否形成一些有价值工作。
3. release和测试过程密不可分,Rails的release流程就明确说明,要先通过CI等测试才能release,所以CI应该是release的一个重要因素,我觉得这个点应该可以和国外那边工作结合起来,但具体怎样结合还需要进一步思考。
1.目前我版本库里的代码(https://www.trustie.net/projects/800/repository/github-ci-crawller),实现了基本的解析github中Rails项目的CI log信息,包括爬取builds file,然后解析得到job id,根据job id再爬取job file,然后解析job得到每个test信息(测试文件信息、测试时间、错误个数等);
2.下一步我将对代码进行优化,然后部署到122,实现自动爬取Rails项目的所有job;

