
项目简介
将github的isssues信息爬取下来,然后进行分析

本科毕设论文初稿,请王涛老师帮忙把下关,提出宝贵意见,我好修改修改
上传了基于范强学长意见的修改稿
曾令斌_初稿_本科毕业设计论文.docx
(
1.782 MB)
曾令斌毕业设计_第一次修改.docx
(
1.979 MB)
pr代指pull request
1.获取1000多个项目的issues和pr的评论
2.获取1000多个项目的针对代码行的特定评论
3.获取1000多个项目中全部用户的信息
4.对每个项目,每个评论者的评论数量和针对评具体代码行的数量进行分析,如下图
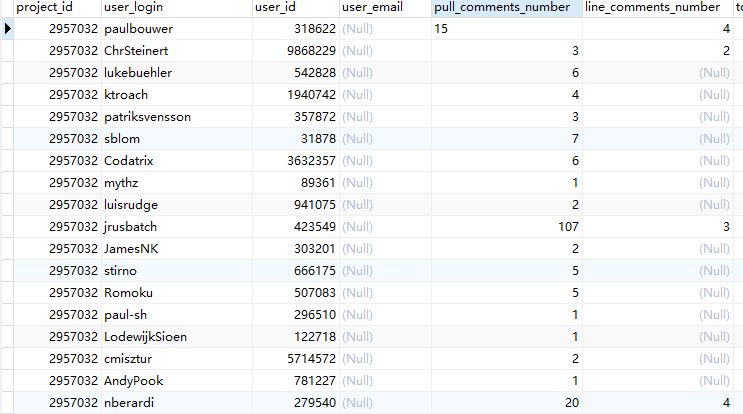
5.对每个用户的e_mail进行合并分类,提取出前缀一样的 e_mail,并进行分析,
6.对pr下面的comments进行分类,初步如下图:


可参考其中的方法
以下两篇文章,请翻译。
ICSE 2013-codereview.pdf
(
842.988 KB)
代码审阅中自动推荐审查者的系统.docx
(
532.31 KB)


开题报告 曾令斌 第一版修改.docx
(
53.024 KB)
开题报告 曾令斌 第一版修改-wt.docx
(
51.367 KB)
开题报告 曾令斌 第二次修改.docx
(
59.96 KB)
发帖时间:2015-12-04 23:35
更新时间:2015-12-04 23:35
本周的情况在于完成一个多线程的爬虫,已经粗略的爬过一遍,不过较为粗略,一部分issues和comments由于超时问题和access_token耗尽的问题,而未能爬下来,未来三天打算进行查漏补缺。
下周,学习R语言,掌握R语言的基本操作和与mysql数据库的交互

发帖时间:2015-12-01 00:28
更新时间:2015-12-01 00:28
今晚mysql服务器报错,百度上竟然没有,最后只能看英文的 ,最后发现是,是由于短时间开启的线程太多,insert太频繁。最后给insert操作加了锁,才初步解决问题。进度有点慢,老师学长们多包容包容
,最后发现是,是由于短时间开启的线程太多,insert太频繁。最后给insert操作加了锁,才初步解决问题。进度有点慢,老师学长们多包容包容
,最后发现是,是由于短时间开启的线程太多,insert太频繁。最后给insert操作加了锁,才初步解决问题。进度有点慢,老师学长们多包容包容 ,传上去了,最新的,名字叫做,github spider.py,谢谢学长
,传上去了,最新的,名字叫做,github spider.py,谢谢学长
发帖时间:2015-11-30 16:10
更新时间:2015-11-30 16:10
过去一个星期,主要是指余跃学长的指导下,编写爬虫,完成了一个单线程的python爬虫,掌握了数据库的相关操作。但是单线程的爬虫速度过慢,没办法完成预期目标,所以现在正在进行多线程爬虫的编写
本周:写完多线程爬虫,并将数据爬取下来
加油
发帖时间:2015-11-24 12:23
更新时间:2015-11-24 12:23
本周任务:完成对开源社区数据的爬取,并将其转存到数据库中。
状态:进行中。

